Loading OpenStreetMap data into a Graph Database
Published
One day while designing a mapping/routing application, I thought it would be fun to try to model OpenStreetMap (OSM) data in a graph database. To me, graph structures always seemed like the natural choice for representing roads and intersections
While searching for an Open Source graph database to use, Neo4j quickly emerged as the front runner with it’s vibrant community and solid API.
As far as loading the data, I tried a few of the existing Neo4j OSM importers, but ultimately ended up creating my own. My findings and methodology are described below.
Existing Data Importers
The (un)official Neo4j OSM loader was created by Neo4j contributors, and represented the default option. After digging in, it seemed to have been created at an awkward time. It incorporated the functionality of the now dated Neo4j Spatial plugin, but did not take advantage the native geospatial indexing available in Neo4j’s 3.4+.
Despite some interesting YouTube presentations, the OSM loader was not well documented, and the data model it produced was extremely complex. It ultimately was overkill for my routing application.
Designing a Graph Data Importer
After familiarizing myself with the OSM data schema, and finding conveniently sized exports, I started design iterations on my own importer.
I ended up with a Java application that imports OSM data (in XML format), and produces a simple schema that includes nodes, ways, and all their attached properties/tags.
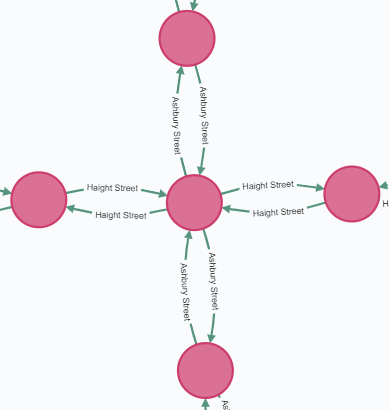
Loading the Nodes (Intersections)
On the first pass, the OSM Nodes are loaded into the graph. The Nodes represent intersections, and carry a POINT geometry (a set of latitude and longitude coordinates). An index gets created to help with quick retrieval by OSM ID.

Loading the Ways (Roads)
Ways represent streets or footpaths, and are created as Relationships within the graph. Loading the Ways was much more complicated because they connect existing Nodes, and carry slightly more complex geometries (lines instead of points).
In the source data, Ways are made up of a list of Nodes (referenced as <nd> elements) and a collection of metadata tags.
<way id="88572932" version="1">
<nd ref="65325032"/>
<nd ref="6587947112"/>
<nd ref="6587947113"/>
<nd ref="65321839"/>
<nd ref="65363163"/>
<nd ref="5429618398"/>
<nd ref="4911322451"/>
<nd ref="6587947104"/>
<nd ref="65293746"/>
<tag k="name" v="Mission Street"/>
<tag k="highway" v="secondary"/>
<tag k="surface" v="asphalt"/>
<tag k="tiger:cfcc" v="A41"/>
<tag k="tiger:county" v="San Francisco, CA"/>
<tag k="trolley_wire" v="yes"/>
<tag k="tiger:name_base" v="Mission"/>
<tag k="tiger:name_type" v="St"/>
</way>I needed to loop through this list of Nodes, retrieve each referenced Node from within the graph, and create a Relationship between them.
I later realized that a set of 2 Relationships had to be created in-between each pair of Nodes so that the graph could be traversed in both directions. The <way> shown above resulted in 16 total Relationships being created (8 in each direction).

In addition to juggling Node references, Ways also have a slightly more complex geometry. The LINESTRING geometry is a list of 2 or more points. In this case, the POINT geometries of the referenced Nodes are used.
Since these Relationships are ultimately going to be used for routing, I took this opportunity to assign a length (or cost) to each. I used a set calculation to approximate the length of each Relationship.
SAX Style XML Parsing
The traditional approach for parsing XML files is to load the entire file into memory prior to reading the data and performing XPath queries. This approach quickly became an issue when working with large OSM XML data files (e.g. the city of San Francisco is north of 500mb).
I was able to alleviate this problem by switching to SAX style parsing, where XPath queries are executed against the file sequentially as it is read. Logic is executed immediately whenever a matching XML node is encountered, which in my case where <node> and <way> elements.
Graph Transactions and Commit Intervals
At first, the graph data loader took several hours to process 500mb of data, and ran at a very low CPU load (less than 10%). I realized the culprit was performing database commits after creating each Node and Relationship.
I adjusted the code to share a transaction across around 3000 Node creation operations, and up to 50 Relationship creations. Bundling these transactions into single database commits greatly improved the performance of the loader.
The Code
The latest code is posted on Github, along with a detailed README file that includes build instructions, sample import commands, and a few Cypher queries to help explore the graph.
Concerns and Next Steps
While the importer was fun to write, and I learned a lot about the OSM data-set, I did have a few reservations:
- The importer does not take advantage of any of Neo4j Spatial indexing, or the Spatial Plugin – the geometries are simply stored on each Node and Relationship in WKT format
- The schema produced is simple, but still custom – it does not match any kind of community standard (meaning code written against it is not standardized/portable)
Now that I have a fully loaded graph, I plan to focus on enriching the data to include more of the features included in OSM data. For example, I would like to mark which roads (Relationships) run alongside lakes, historical buildings, or shopping districts. I have a few strategies in mind on how to accomplish this task, and will check back in with the results!
Comments
No responses yet